
排序
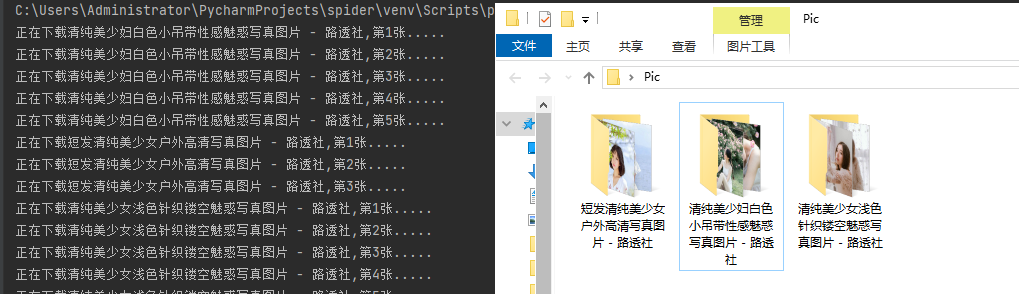
Python爬虫教程六:多线程爬虫案例实例
一、python多线程 关于多线程的知识,看下面这篇文章即可。 二、多线程实例 这里我们是把本站python爬虫教程四中的爬虫例子,给改编写成使用多线程的模式的。 原代码效果如下: import os impor...
![Python爬虫:requests.get()爬取连接内容时,报错[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: certificate has expired (_ssl.c:1129) - 拽熊博客](http://blog.zhuaixiong.com/wp-content/uploads/2022/10/2022101408555682.png)
Python爬虫:requests.get()爬取连接内容时,报错[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: certificate has expired (_ssl.c:1129)
问题背景 如果目标网站没有设置好HTTPS证书,又或者网站的HTTPS证书不被CA机构认可,用浏览器访问的话,就可能会出现SSL证书错误的提示。 用requests库来请求这类网站的话,会直接抛出SSLError...
python多线程超级详细!
一、什么是多线程? 多线程类似于同时执行多个不同程序,多线程运行有如下优点: 使用线程可以把占据长时间的程序中的任务放到后台去处理。用户界面可以更加吸引人,比如用户点击了一个按钮去触...
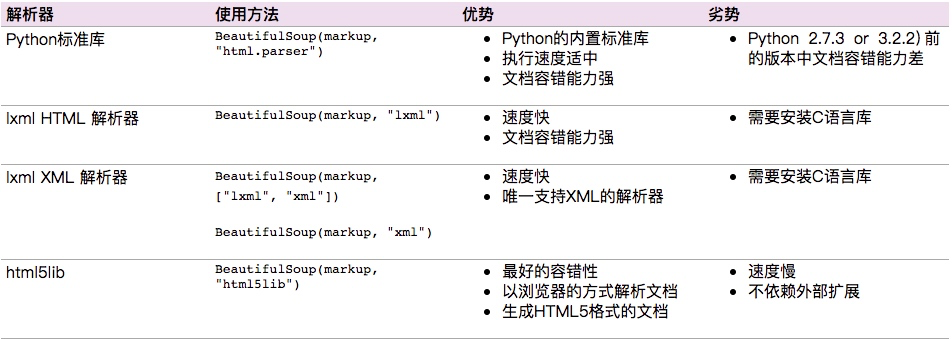
Python爬虫教程五:数据清洗 – BeautifulSoup模块
和lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据 区别在于:BeautifulSoup4可以使用CSS 选择器,lxml使用xpath 一、安装 安装 Beautiful S...
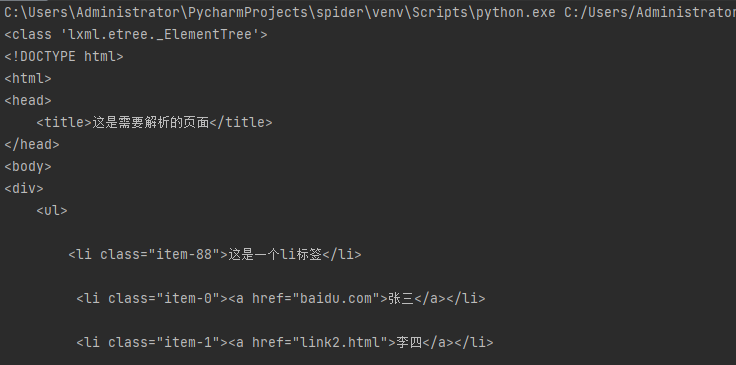
Python爬虫教程四:数据清洗-xpath表达式
xpath表达式:我们可以先将 HTML文件转换成 XML文档,然后用 XPath 查找 HTML 节点或元素。我们需要安装lxml模块来支持xpath的操作。 from lxml import etree 一、转换特定html对象 方法一:etr...

Python爬虫教程三:数据清洗-正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。 python 中封装了re模块。 常用方法 re.match() 尝试从字符串的起始位置匹配一个模式,如果不是起始位置...
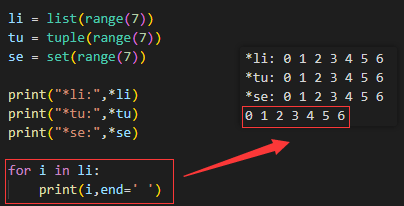
Python * 、** 解包 与 *args、**kargs详解
一、*和**解包操作 解包操作可以应用于元组、列表、集合、字典。 *:用于列表、元组、集合**:用于字典 1.取出列表中的元素 2.收集列表中多余的值 二、*args和**kargs用于函数可变传参 在Python...
Python 迭代器与生成器详解!
什么是迭代 迭代是可以通过遍历的方式依次把某个对象中的元素取出的方法,在python中,迭代是通过使用for....in....语句完成的 可迭代对象 可以被直接作用于for语句的对象都可以被称为可迭代对...