
排序

Python标准库shutil的使用( 文件复制删除、文件夹复制删除、压缩包 压缩解压处理模块)
shutil库是python标准库,可以直接完成复制符间的操作,同时还支持归档。 一、复制类 1.copy(src, dst):将文件src复制至dst。dst可以是个目录,会在该目录下创建与src同名的文件,若该目录下存...

Python轻量级Web框架:Bottle库!
Bottle是一个超轻量级的python库。说是库,其本身只由一个4000行左右的文件构成,并且不需要任何依赖,只靠python标准库即可运作。和它本身的轻便一样,Bottle库的使用也十分简单。相信在看到本...
17 个Python 在线编程网站!实现随时随地编程!
安装 Python 很容易,但或许你正在用智能手机/平板电脑,在用不允许安装软件的电脑,或者因为其它原因无法安装 Python。那么,如何通过免安装的方式使用 Python 呢? 本文将介绍 17 个免费的 Py...
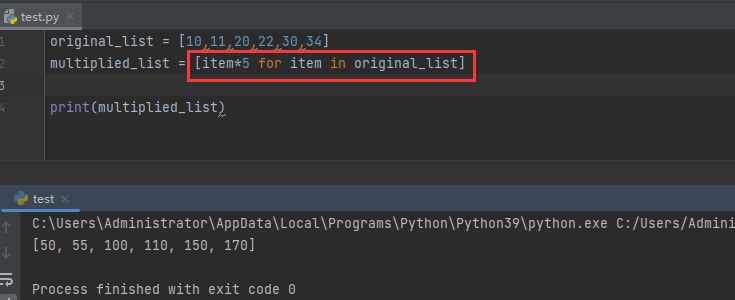
4 个 Python 推导式开发技巧
什么是列表推导式? 列表推导式List Comprehension是创建列表的一种优雅且最符合python语言的方法。与for循环和if语句相比,列表推导式在基于现有列表的值创建新列表时语法要短得多。因此,让我...
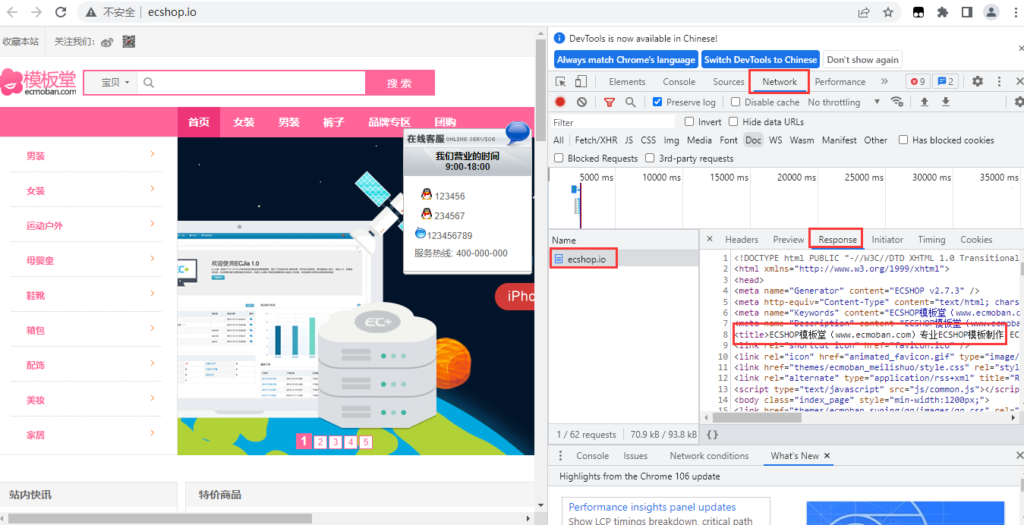
两种办法,快速一键生成Python爬虫请求头!
我们在写爬虫,构建网络请求的时候,不可避免地要添加请求头( headers ),这里介绍工具一键生成请求头,省去编写请求头信息的麻烦! 方法一:网站在线转换 工具网址:https://curlconverter.com...

Python爬虫教程三:数据清洗-正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。 python 中封装了re模块。 常用方法 re.match() 尝试从字符串的起始位置匹配一个模式,如果不是起始位置...
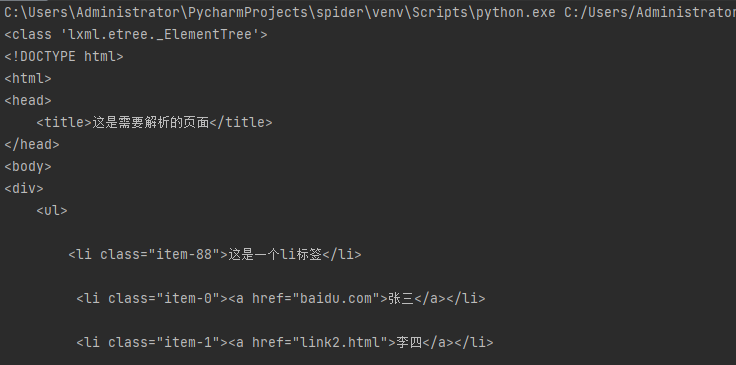
Python爬虫教程四:数据清洗-xpath表达式
xpath表达式:我们可以先将 HTML文件转换成 XML文档,然后用 XPath 查找 HTML 节点或元素。我们需要安装lxml模块来支持xpath的操作。 from lxml import etree 一、转换特定html对象 方法一:etr...
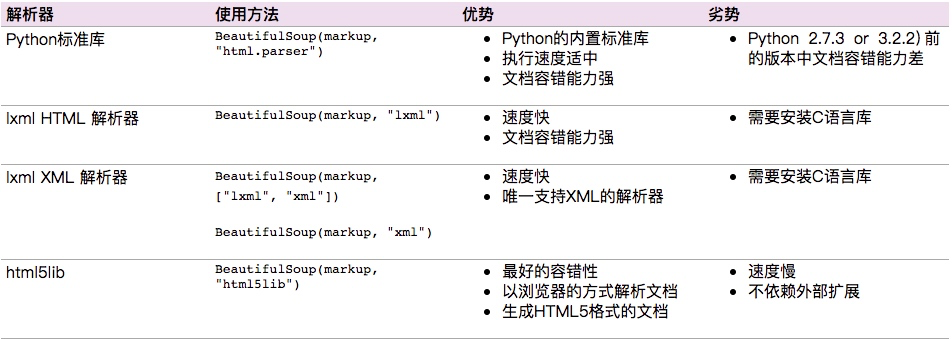
Python爬虫教程五:数据清洗 – BeautifulSoup模块
和lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据 区别在于:BeautifulSoup4可以使用CSS 选择器,lxml使用xpath 一、安装 安装 Beautiful S...