

Python爬虫共8篇
排序

Python爬虫教程八:Scrapy框架(下)
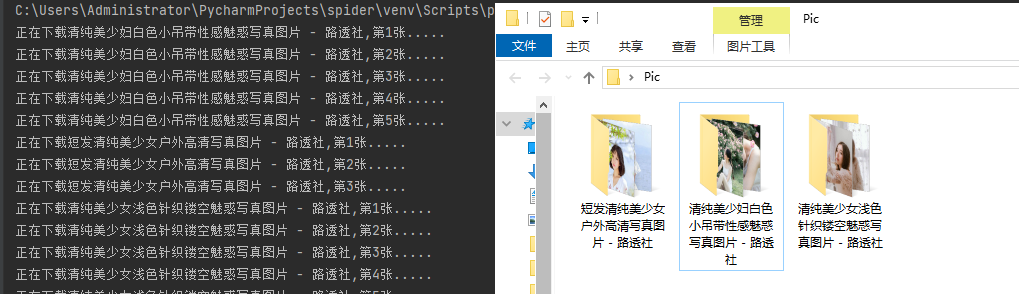
一、数据清洗方式 spider代码 import scrapy class PicspiderSpider(scrapy.Spider): name = 'picSpider' # 爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字 allowed_domains = ...
Python爬虫教程七:Scrapy框架(上)
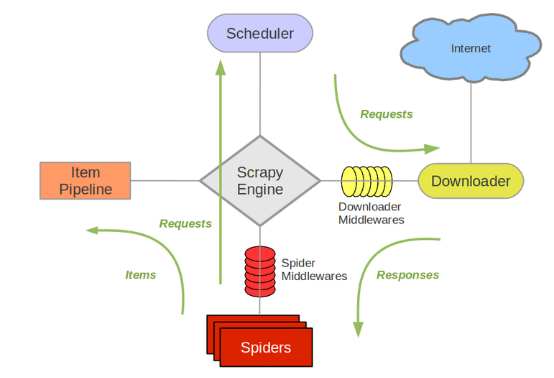
一、Scrapy框架简介 Scrapy是用Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。 框架的优势在于,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来...
Python爬虫教程六:多线程爬虫案例实例
一、python多线程 关于多线程的知识,看下面这篇文章即可。 二、多线程实例 这里我们是把本站python爬虫教程四中的爬虫例子,给改编写成使用多线程的模式的。 原代码效果如下: import os impor...
Python爬虫教程五:数据清洗 – BeautifulSoup模块
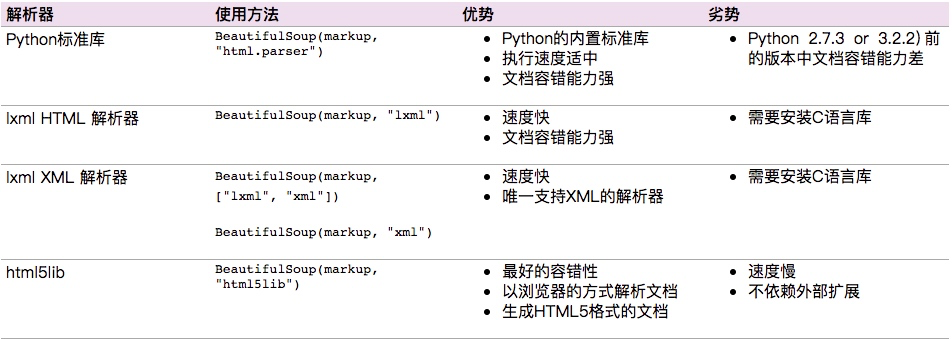
和lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据 区别在于:BeautifulSoup4可以使用CSS 选择器,lxml使用xpath 一、安装 安装 Beautiful S...
Python爬虫教程四:数据清洗-xpath表达式
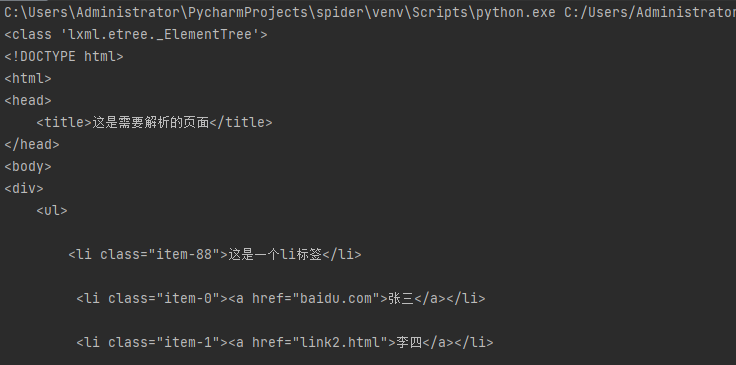
xpath表达式:我们可以先将 HTML文件转换成 XML文档,然后用 XPath 查找 HTML 节点或元素。我们需要安装lxml模块来支持xpath的操作。 from lxml import etree 一、转换特定html对象 方法一:etr...

Python爬虫教程三:数据清洗-正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。 python 中封装了re模块。 常用方法 re.match() 尝试从字符串的起始位置匹配一个模式,如果不是起始位置...

Python爬虫教程二:requests库数据挖掘
什么是Requests Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库如果你看过上篇文章关于urllib库的使用,你会发现,其实urllib还是非常不方便的,而Request...
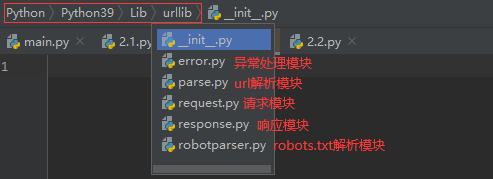
Python爬虫教程一:urllib库数据挖掘
一、什么是Urllib Urllib是python内置的HTTP请求库,包括以下模块 二、request模块 1.urlopen方法 用于直接打开网址。 import urllib.request response = urllib.request.urlopen('http://www.b...