

Python共41篇

一文读懂 Python 装饰器
装饰器:本质上也是一种函数,它可以让其它函数在不经过修改的情况下增加一些功能。 像我们常见的@classmethod、@static装饰器。被装饰器修饰的函数,都增加了他们相应的能力 装饰器的基本使用...
Python 迭代器与生成器详解!
什么是迭代 迭代是可以通过遍历的方式依次把某个对象中的元素取出的方法,在python中,迭代是通过使用for....in....语句完成的 可迭代对象 可以被直接作用于for语句的对象都可以被称为可迭代对...
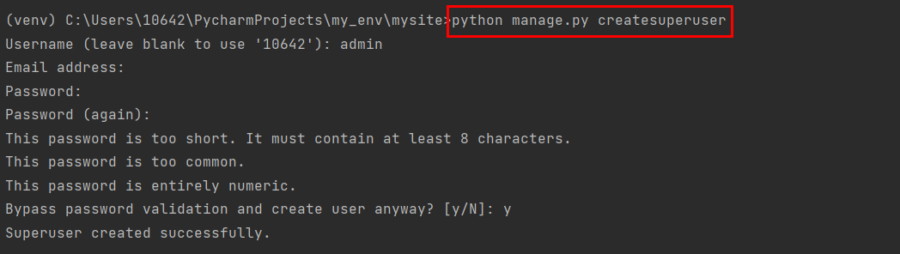
针对模型创建管理站点
之前已经定义了Post模型,通过读取模型元数据,同时提供针对编辑内容的产品接口,Django可自动构建管理站点。用户可直接对其加以使用,并配置模型的显示方式。 一、创建超级用户 python manage....
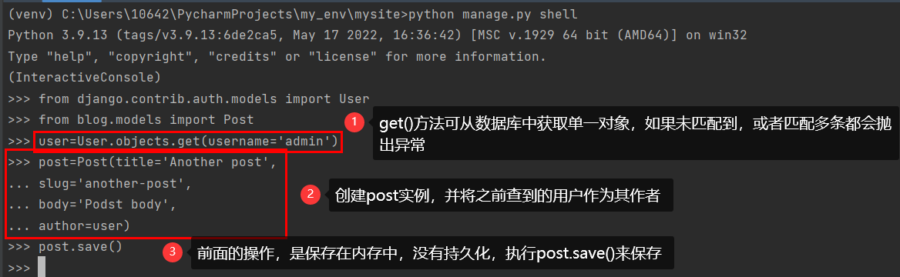
与QuerySet和管理器协同工作
本节将讨论如何从数据库中获取信息并与其进行交互。 Django设置了强大的数据库抽象API,并以此方便地创建、获取、更新及删除对象。同时,Django的对象关系映射器(ORM)兼容于Mysql/PostgreSQL/...

django安装及项目创建
一、安装django 1.创建隔离的python环境 直接使用pycharm创建虚拟环境my_env 创建的目录,包含自身的python二进制文件,可独立持有自己的包 2.利用pip安装Django 点击 Pycharm下面终端进入虚拟...
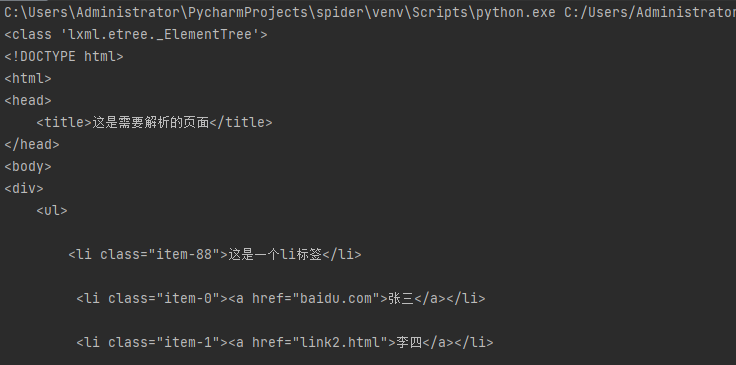
Python爬虫教程四:数据清洗-xpath表达式
xpath表达式:我们可以先将 HTML文件转换成 XML文档,然后用 XPath 查找 HTML 节点或元素。我们需要安装lxml模块来支持xpath的操作。 from lxml import etree 一、转换特定html对象 方法一:etr...

Python爬虫教程八:Scrapy框架(下)
一、数据清洗方式 spider代码 import scrapy class PicspiderSpider(scrapy.Spider): name = 'picSpider' # 爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字 allowed_domains = ...
两种办法,快速一键生成Python爬虫请求头!
我们在写爬虫,构建网络请求的时候,不可避免地要添加请求头( headers ),这里介绍工具一键生成请求头,省去编写请求头信息的麻烦! 方法一:网站在线转换 工具网址:https://curlconverter.com...
热门排行




今天仅剩
100%
本周还有
100%
本月剩余
100%
今年还剩
100%