

Python共41篇

Python爬虫教程八:Scrapy框架(下)
一、数据清洗方式 spider代码 import scrapy class PicspiderSpider(scrapy.Spider): name = 'picSpider' # 爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字 allowed_domains = ...
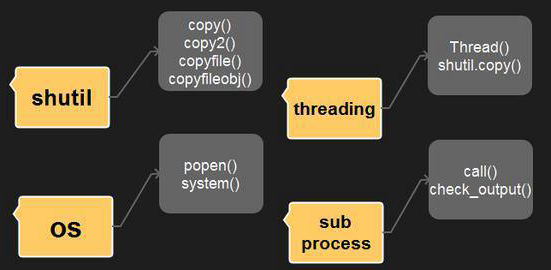
Python复制文件的5种方法
以下是“如何在Python中复制文件”的4种库的使用。+open方法来复制文件 一、shutil标准库 具体使用方法,请查看如下shutil库介绍教程。 二、os库 1.os.popen() 2.os.system() 直接用命令行来执...
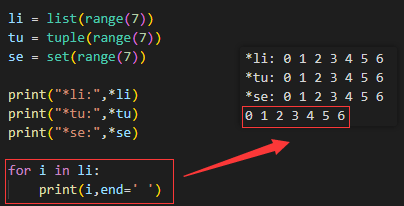
Python * 、** 解包 与 *args、**kargs详解
一、*和**解包操作 解包操作可以应用于元组、列表、集合、字典。 *:用于列表、元组、集合**:用于字典 1.取出列表中的元素 2.收集列表中多余的值 二、*args和**kargs用于函数可变传参 在Python...

使用SimpleHTTPServer进行文件传输
简介 除了ssh和scp、ftp常见的传输文件方法外,还有python下SimpleHTTPServer小工具也可以快捷的传输文件! SimpleHTTPServer是Python 2自带的一个模块,是Python的Web服务器。在Python 3已经合...
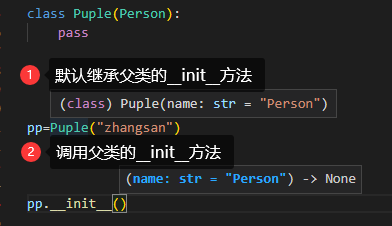
python中继承详解super().__init__()
super().__init__(),就是继承父类的init方法,同样可以使用super()点 其他方法名,去继承其他方法。 我们这里通过实例来了解如何在子类中使用父类方法的方式。 首先定义一个父类: class Perso...

Python标准库shutil的使用( 文件复制删除、文件夹复制删除、压缩包 压缩解压处理模块)
shutil库是python标准库,可以直接完成复制符间的操作,同时还支持归档。 一、复制类 1.copy(src, dst):将文件src复制至dst。dst可以是个目录,会在该目录下创建与src同名的文件,若该目录下存...
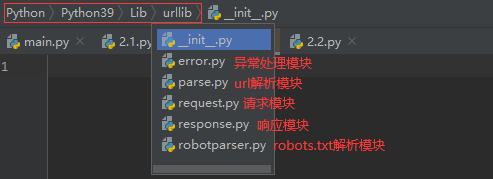
Python爬虫教程一:urllib库数据挖掘
一、什么是Urllib Urllib是python内置的HTTP请求库,包括以下模块 二、request模块 1.urlopen方法 用于直接打开网址。 import urllib.request response = urllib.request.urlopen('http://www.b...
60个必备!用Python的一些日常高频写法,建议收藏备用!
一、 数字 1 求绝对值 绝对值或复数的模 In [1]: abs(-6) Out[1]: 6 2 进制转化 十进制转换为二进制: In [2]: bin(10) Out[2]: '0b1010' 十进制转换为八进制: In [3]: oct(9) Out[3]: '0o11' ...
热门排行




今天仅剩
100%
本周还有
100%
本月剩余
100%
今年还剩
100%