

Python共41篇 第5页
设计博客数据方案
即定义博客的数据模型,这里模型表示为一个python类,并且继承自django.db.models.Model,其中的每个属性视为一个数据库字段。 Django对每个模型(类)创建一个表,当创建一个模型时,Django提...
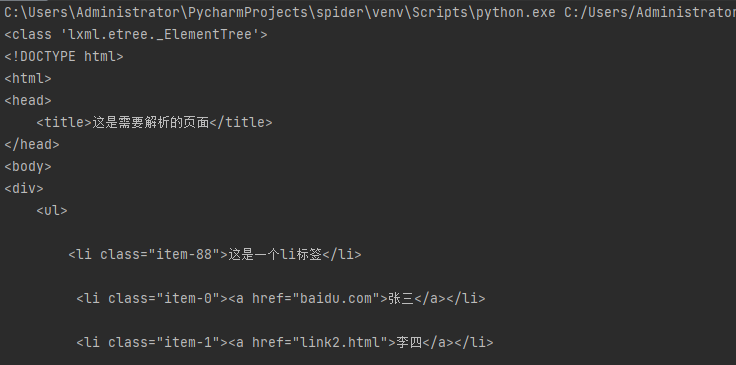
Python爬虫教程四:数据清洗-xpath表达式
xpath表达式:我们可以先将 HTML文件转换成 XML文档,然后用 XPath 查找 HTML 节点或元素。我们需要安装lxml模块来支持xpath的操作。 from lxml import etree 一、转换特定html对象 方法一:etr...
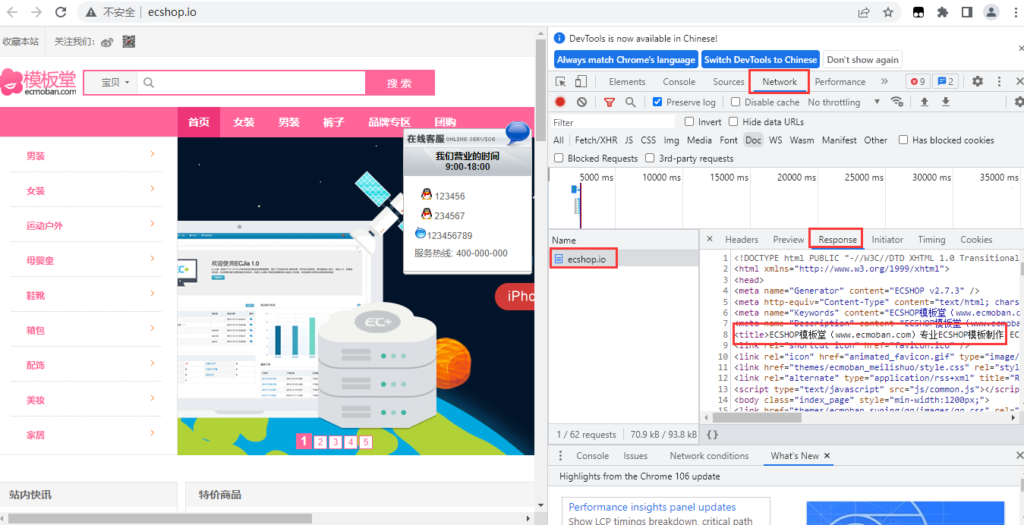
两种办法,快速一键生成Python爬虫请求头!
我们在写爬虫,构建网络请求的时候,不可避免地要添加请求头( headers ),这里介绍工具一键生成请求头,省去编写请求头信息的麻烦! 方法一:网站在线转换 工具网址:https://curlconverter.com...

for else语法、try ….except….else语法 和 while….else语法
这三种语句都是差不多的。都是前面的内容是正常执行完成的就会执行else语句,如果是非正常,比如:执行失败,或者break跳出,那么都是不会执行else语句的! 1.for … else 如果for循环是正常执...
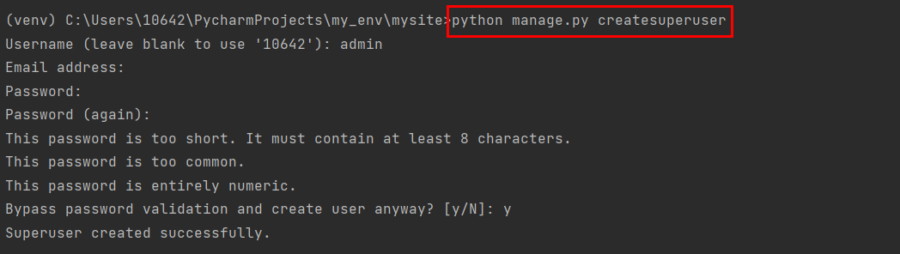
针对模型创建管理站点
之前已经定义了Post模型,通过读取模型元数据,同时提供针对编辑内容的产品接口,Django可自动构建管理站点。用户可直接对其加以使用,并配置模型的显示方式。 一、创建超级用户 python manage....
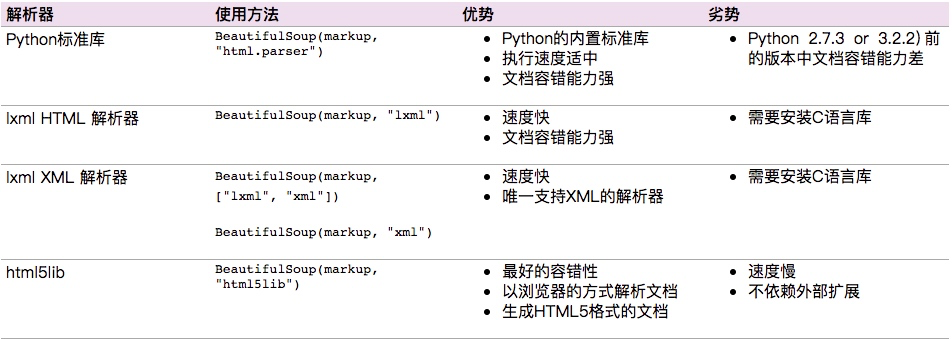
Python爬虫教程五:数据清洗 – BeautifulSoup模块
和lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据 区别在于:BeautifulSoup4可以使用CSS 选择器,lxml使用xpath 一、安装 安装 Beautiful S...
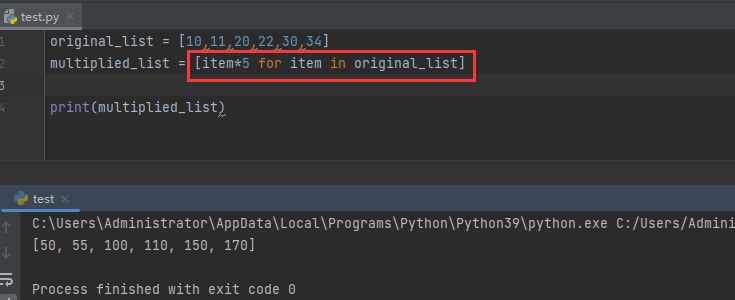
4 个 Python 推导式开发技巧
什么是列表推导式? 列表推导式List Comprehension是创建列表的一种优雅且最符合python语言的方法。与for循环和if语句相比,列表推导式在基于现有列表的值创建新列表时语法要短得多。因此,让我...

Python时间与日期操作(datetime、time、calendar)
简介 time模块与datetime模块区别: time模块是通过调用C库实现的,所以有些方法在某些平台上可能无法调用,但是其提供的大部分接口与C标准库time.h基本一致。与time模块相比,datetime模块提供...
热门排行




今天仅剩
100%
本周还有
100%
本月剩余
100%
今年还剩
100%