
排序

Python爬虫教程八:Scrapy框架(下)
一、数据清洗方式 spider代码 import scrapy class PicspiderSpider(scrapy.Spider): name = 'picSpider' # 爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字 allowed_domains = ...
Python爬虫教程七:Scrapy框架(上)
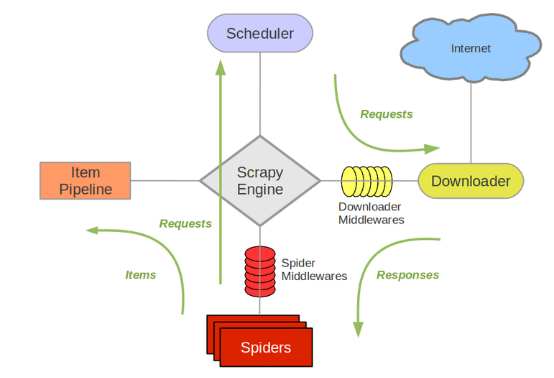
一、Scrapy框架简介 Scrapy是用Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。 框架的优势在于,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来...
基于scrapy的redis安装和配置方法
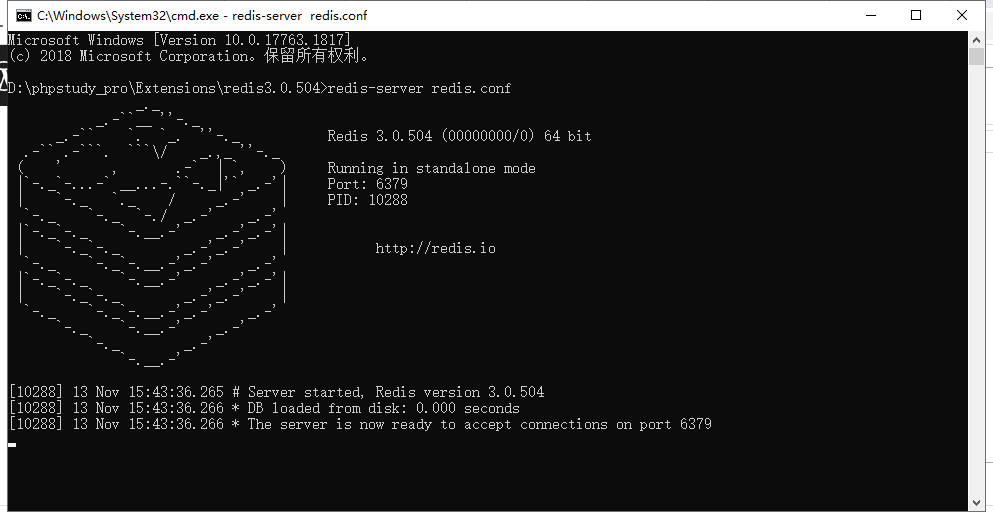
在定向爬虫的制作过程中,使用分布式爬取技术可以显著提高爬取效率。而 Redis 配合 Scrapy 是实现分布式爬取的基础。 Redis 是一个高性能的 Key-Value 数据库,它把数据保存在内存里。因此可以...