
排序
Python爬虫教程五:数据清洗 – BeautifulSoup模块
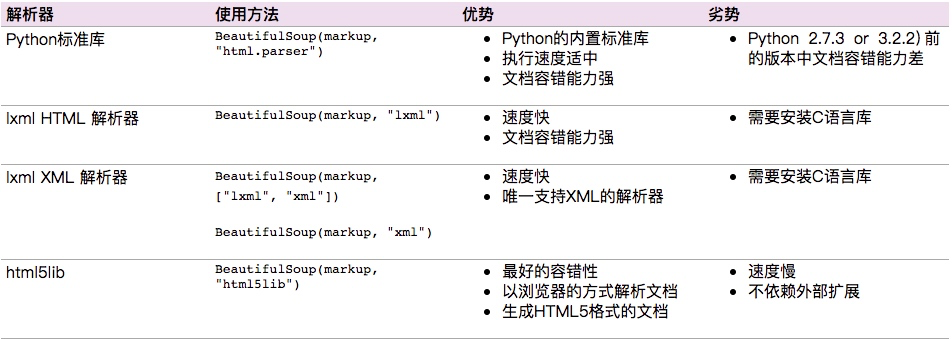
和lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据 区别在于:BeautifulSoup4可以使用CSS 选择器,lxml使用xpath 一、安装 安装 Beautiful S...
Python爬虫教程四:数据清洗-xpath表达式
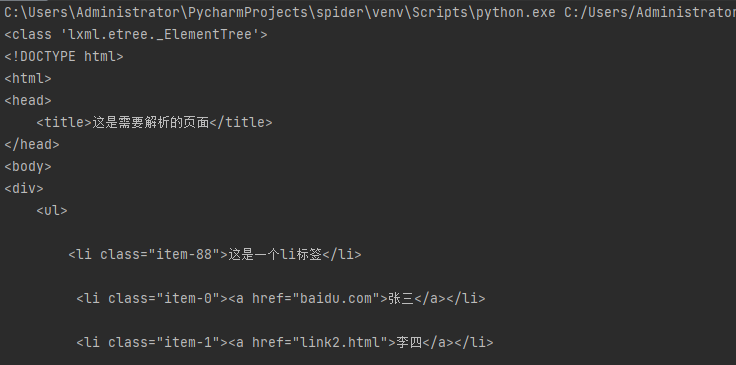
xpath表达式:我们可以先将 HTML文件转换成 XML文档,然后用 XPath 查找 HTML 节点或元素。我们需要安装lxml模块来支持xpath的操作。 from lxml import etree 一、转换特定html对象 方法一:etr...