单业务场景性能测试是整个性能测试的基础,通过测试可以发现单业务接口能承受的最大压力。
单业务瞬时加压
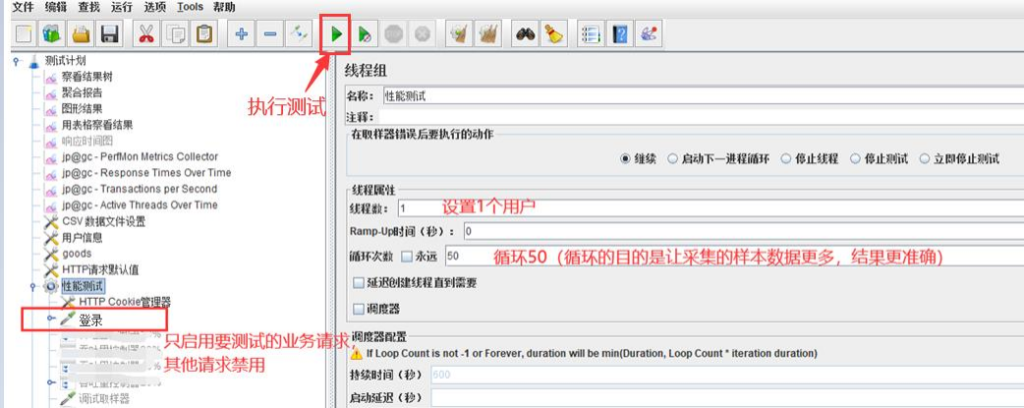
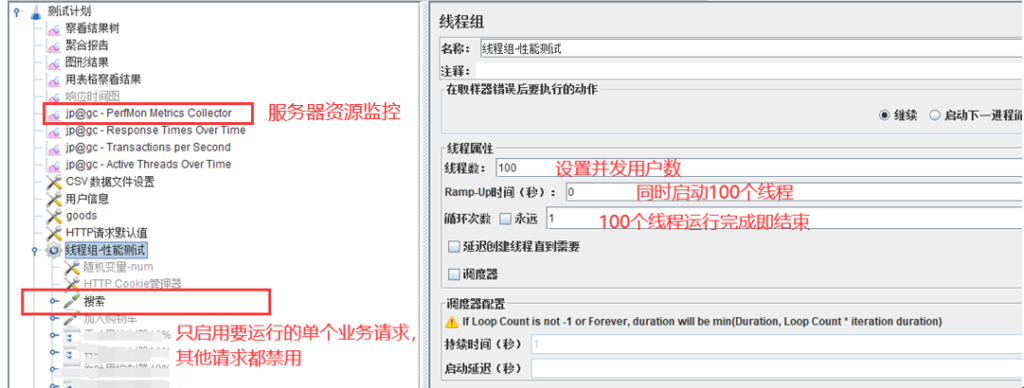
1、添加标准线程组,只启用搜索请求,并进行脚本优化(参数化、断言等)。
2、加压方案示例
(1)线程数设置为 100,Ramp-up 设为 0,循环 1 次
(2)添加监听器如下组件:
- jp@gc – Active Threads Over Time
- jp@gc – Response Times Over Time
- jp@gc – Transactions per Second
- jp@gc – PerfMon Metrics Collector(执行前要启动 startAgent)
3、测试完成后,查看结果数据如下:
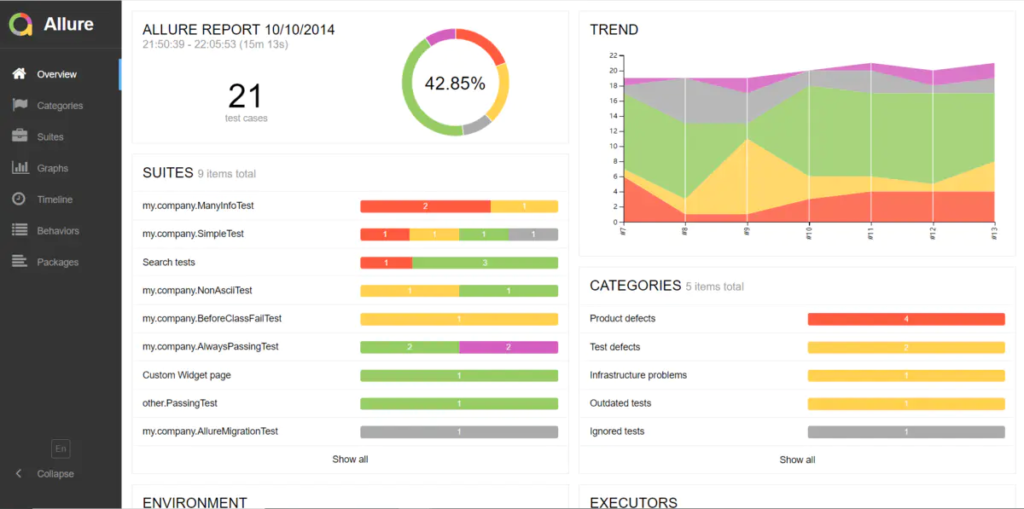
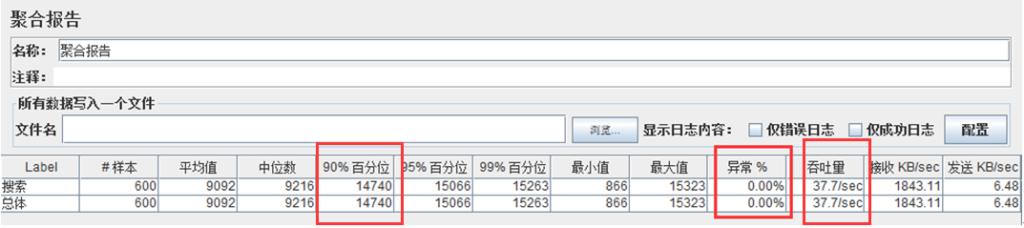
(1)查看聚合报告数据(监听器 -> 聚合报告)

(2)查看 TPS 图表(监听器 -> Transactions per Second)
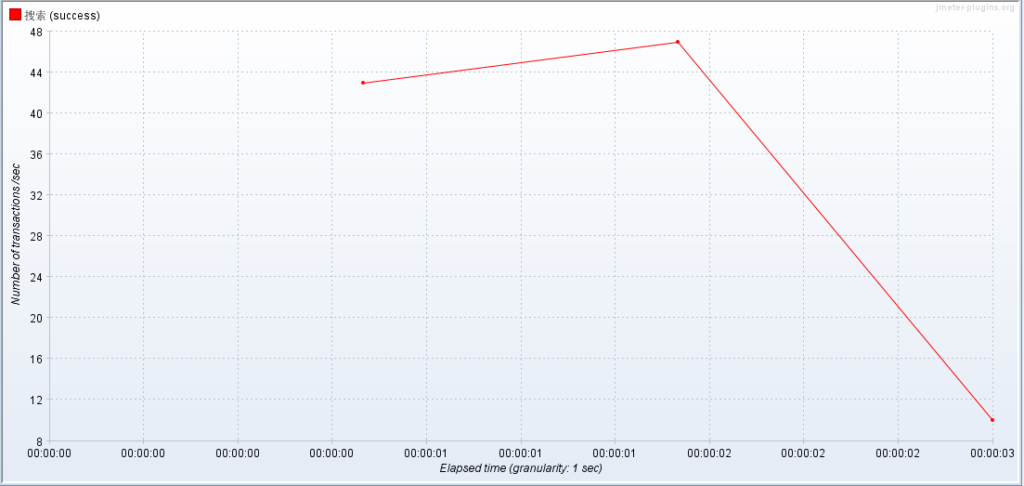
(3)查看响应时间图表(监听器 -> Response Times Over Time)

(4)查看服务器资源使用情况(监听器 -> PerfMon Metrics Collector)
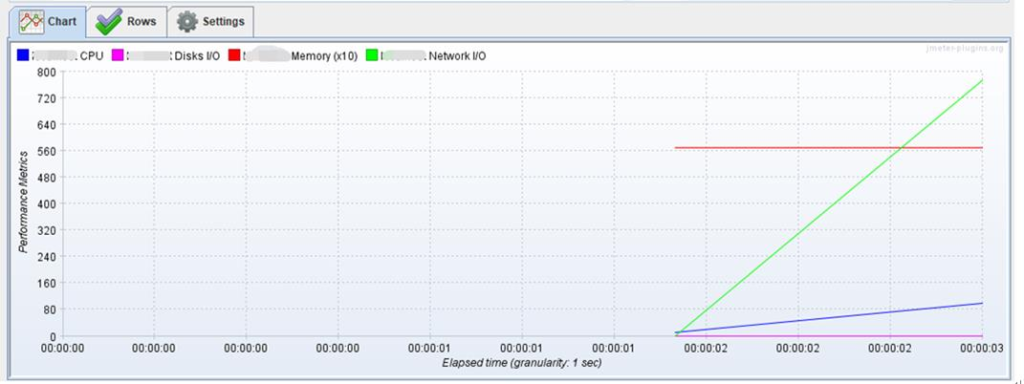
导出资源监控数据如下:

(5)设置 100 并发执行完成后,再继续增加并发数进行测试,直到测出系统支持的最大并发数为止。
针对搜索接口业务,从并发 100 开始加压,一直加到 600 并发的测试结果数据如下:
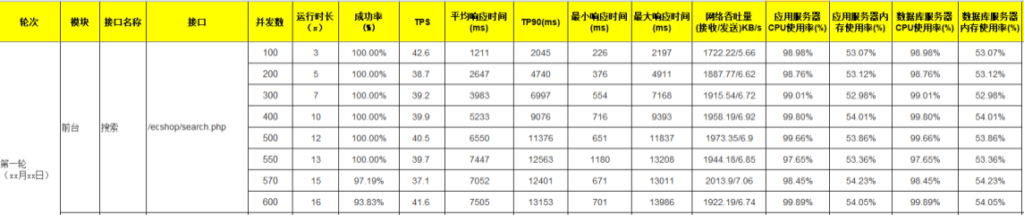
4.结果分析
同时加载 500 并发用户,无异常
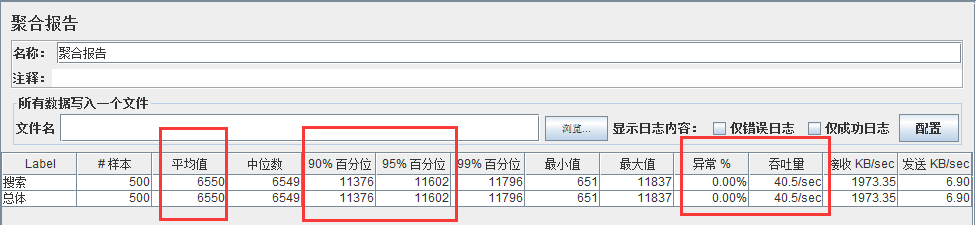
同时加载 550 并发用户,无异常
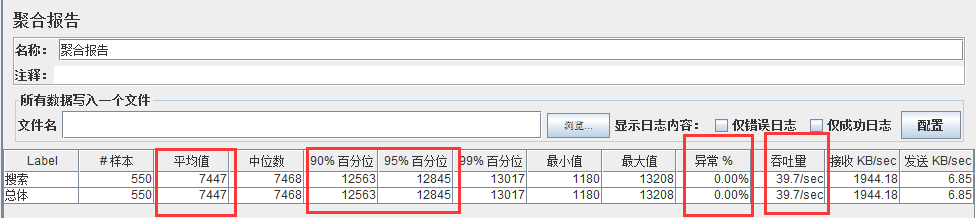
同时加载 570 并发用户,出现 2.81%的异常
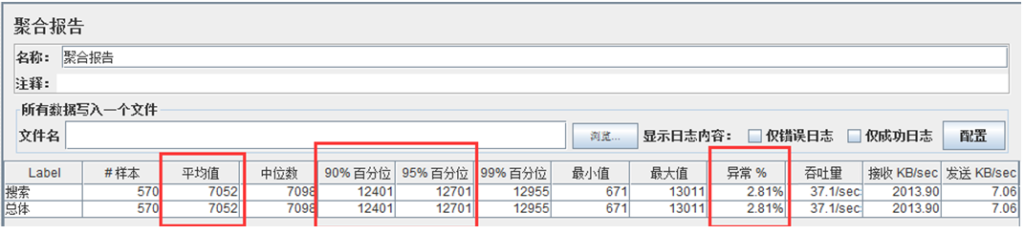
同时加载 600 并发用户,出现 6.17%的异常

在聚合报告中查看到有异常时,去察看结果树中察看异常请求的错误信息如下:

从加载 100 并发到 600 并发的测试过程可以看出,在并发数为 100 时,TPS 为 42.6,是整个测试过程中的最高值,此时 90%响应时间为 2.045,按照响应时间 1-3-5 原则,此时的响应时间是最优的。
随着并发数的增加,TPS 基本上保持在 39 左右,而响应时间在不断的增加,直到加载570 并发的时候,出现 2.81%的异常,再继续增加并发量,异常率也在继续增加。整个测试过程中服务器 CPU 资源的利用率平均都在 98%以上,压测前 CPU 利用率 20%以下,开始加压就瞬间升到 90%以上。而内存利用率相对不高,跟压测前的内存利用率相比,涨幅在 5%以内。由此可看出硬件 CPU 是本次测试的一个瓶颈点。
5.Apache服务器异常处理
通过异常请求的错误信息,可以看出报错的原因是连接应用服务器被拒绝,此时我们去看看 Apache 服务器错误日志,找到有如下的 warn 信息:

从 warn 信息可以看出服务器的请求已经超过了 Apache 设定的最大并发连接数,需要增加Apache 每个子进程的最大并发线程数。
修改 Apache 的配置文件:
(1) 打开文件:Apache 安装路径\conf\http.conf
(2) 查找 Include conf/extra/httpd-mpm.conf,去掉#,保存
(3) 打开文件:Apache 安装路径\conf\extra\httpd-mpm.conf
(4) 找到如下部分内容,增加 ThreadsPerChild 的值,比如修改为 1000
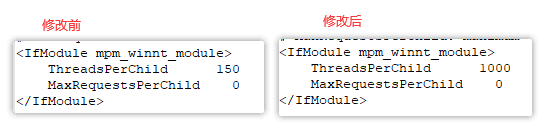
(5) 保存并重启 Apache 服务
再次运行 600 并发,没有异常
修改了 Apache 的连接数,可以增加并发量,但是 TPS 并没有继续增加,响应时间也越来越长,要解决响应时间和 TPS 问题,需要进一步排查接口代码和数据库,可以通过单独对数据库做压测来初步定位是否是数据库的执行占用了过多的响应时间。
单业务阶梯加压
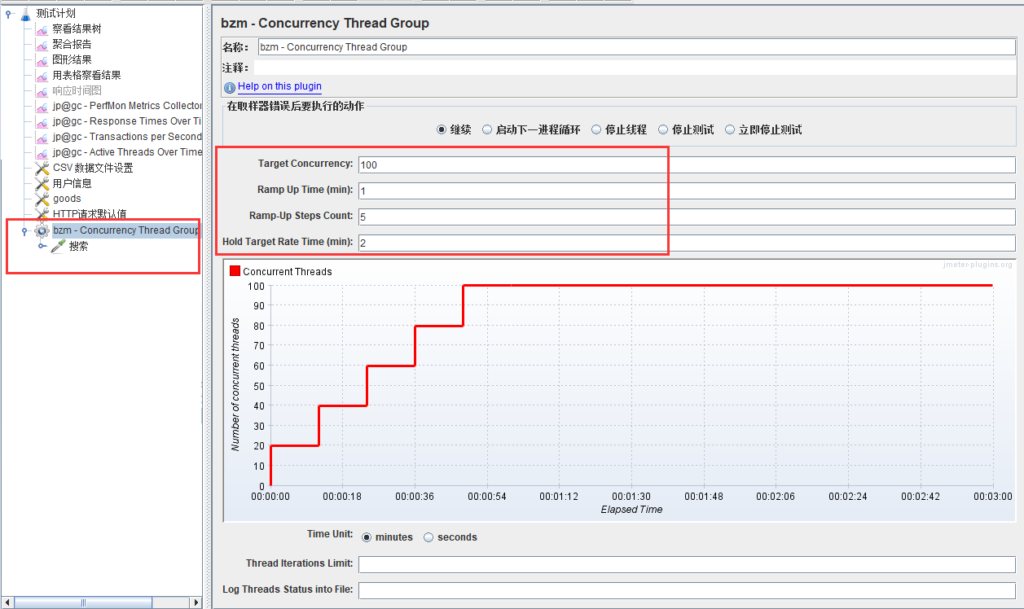
单业务阶梯加压是通过递增并发线程组创建一个目标场景,模仿用户从一定数量开始不断增加到一个目标的并发量,再持续运行一段时间,观察服务器的性能表现。
添加的线程组设置如下:bzm-Concurrency Thread Group
其它步骤与瞬时加压步骤一致,也是添加监视器查看结果,分析原因。并增加并发数继续测试
通过增加目标数量的测试,观察不同用户量情况下服务器的 TPS、响应时间、资源使用情况的变化趋势,从而判断系统能不能达到我们的目标并发数。