最新发布吾生也有涯,而知也无涯!第73页
排序
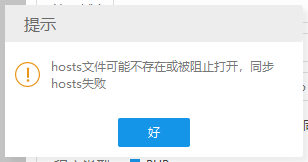
小皮面板(phpstudy)提示:hosts文件可能不存在或被阻止打开,同步hosts失败的解决办法
问题背景 这两天想在本地搭建服务器环境,然后安装了小皮面板后,创建网站会提示:hosts文件可能不存在或被阻止打开,同步hosts失败,今天我们来提供下这个提示的解决方案。 原因分析 小皮面板安...
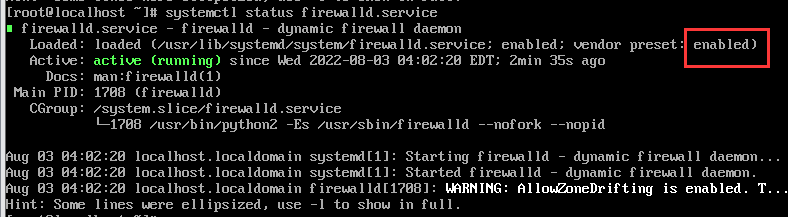
systemctl超级详细讲解
systemd和systemctl systemd是Linux系统最新的初始化系统(init),作用是提高系统的启动速度,尽可能启动较少的进程,尽可能更多进程并发启动,systemd对应的进程管理命令就是systemctl。 Linux ...
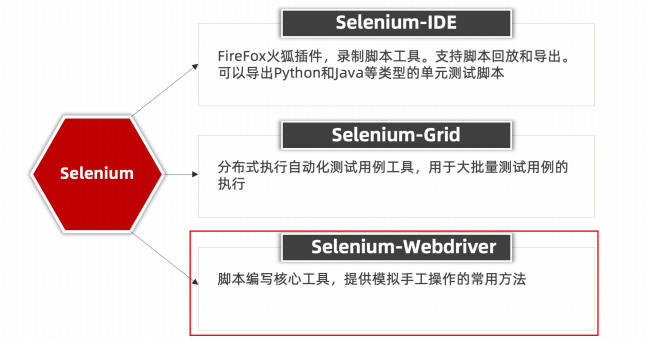
selenium教程一:环境搭建与基础操作步骤
工具介绍 selenium:开源、免费、主流 ⽀持UI,自动化测试工具 selenium工具常用库 selenium-grid可以做分布式(批量在不同平台中运⾏⽤例),⾃动化⽤例较多时、或测试不同浏览器在不同平台运...
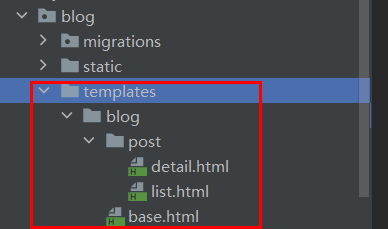
创建视图模版
模板定义了数据的显示方式,它们一般采用HTML编写,并与Django模板语言结合使用。 接下来,在blog应用程序目录中创建下列目录和文件: 上述结构将表示模板的文件结构,其中,base.html文件包含...
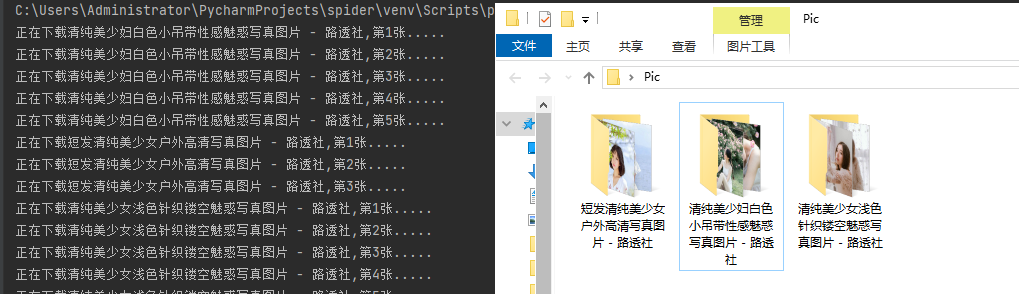
Python爬虫教程六:多线程爬虫案例实例
一、python多线程 关于多线程的知识,看下面这篇文章即可。 二、多线程实例 这里我们是把本站python爬虫教程四中的爬虫例子,给改编写成使用多线程的模式的。 原代码效果如下: import os impor...
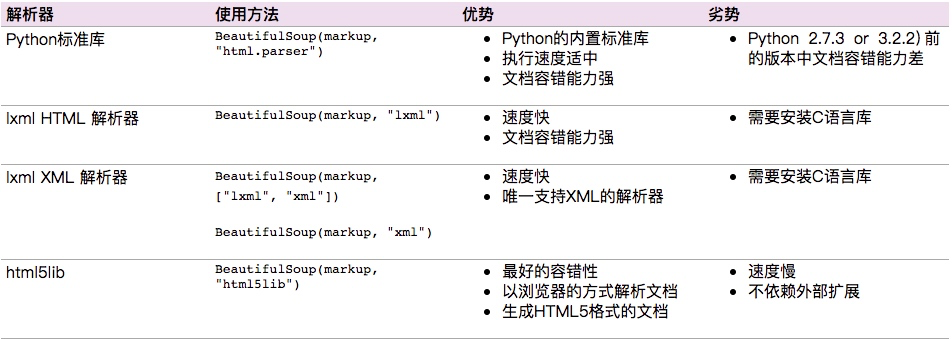
Python爬虫教程五:数据清洗 – BeautifulSoup模块
和lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据 区别在于:BeautifulSoup4可以使用CSS 选择器,lxml使用xpath 一、安装 安装 Beautiful S...
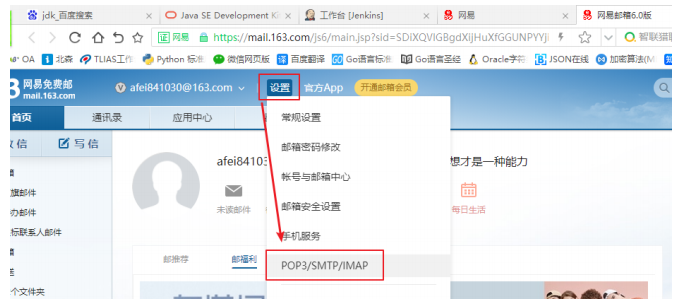
如何获取邮箱的 POP3/SMTP 授权码
获取邮箱POP3/SMTP授权码,可以使我们在不登录邮箱的情况下,配置其它第三方软件来达成发送邮件通知的目的。我们这里以网易邮箱为例,来演示如何获取,其它邮箱类似。 1. 登录 163邮箱,点击 “...



教程分类热点知识快捷入口




今天仅剩
100%
本周还有
100%
本月剩余
100%
今年还剩
100%
随机推荐