xpath表达式:我们可以先将 HTML文件转换成 XML文档,然后用 XPath 查找 HTML 节点或元素。
我们需要安装lxml模块来支持xpath的操作。
from lxml import etree
一、转换特定html对象
方法一:etree.HTML()
解析字符串形式html成了我们需要的html对象
#解析字符串形式html
text ='''
<div>
<ul>
<li class="item-0"><a href="link1.html">张三</a></li>
<li class="item-1"><a href="link2.html">李四</a></li>
<li class="item-inactive"><a href="link3.html">王五</a></li>
<li class="item-1"><a href="link4.html">赵六</a></li>
<li class="item-0"><a href="link5.html">老七</a>
</ul>
</div>
'''
from lxml import etree
#etree.HTML()将字符串解析成了特殊的html对象
html=etree.HTML(text) # <class 'lxml.etree._Element'>
#将html对象转成字符串
result=etree.tostring(html,encoding="utf-8").decode()
print(result)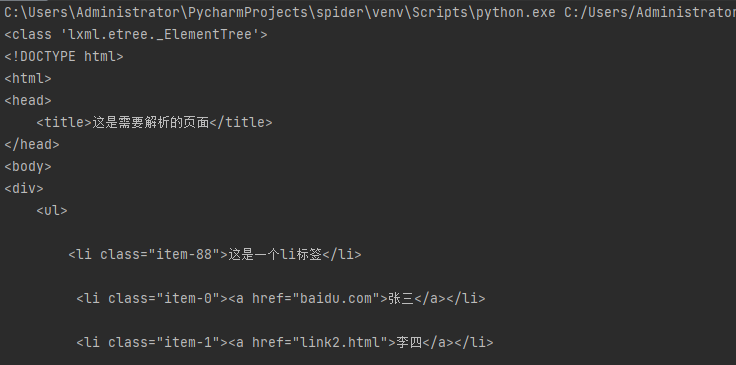
方法二:etree.parse()
解析本地html成了我们需要的html对象
from lxml import etree
#获取本地html文档
html=etree.parse(r"hello.html") # <class 'lxml.etree._ElementTree'>
print(type(html))
result=etree.tostring(html,encoding="utf-8").decode()
print(result)二、html.xpath()获取标签内容
result1=html.xpath("//a") #获取所有a标签
result2=html.xpath("//li/a[@href='link2.html']") #获取指定属性的标签
result3=html.xpath("//li/a/@href") #获取标签的属性
result4=html.xpath("//li[last()-1]/a") #获取倒数第二个li元素下a的内容
print(result1[-2].text) #.text获取标签内容
print(result3[0].tag) #.tag表示获取标签名更多xpath用法,请查看下面教程:

三、实例:爬取美女图片
import os
import requests
from lxml import etree
# https://loutoushe.com/page/366 1-366页
class Spider:
def __init__(self,begin,end):
self.beginPage=begin
self.endPage=end
self.url="https://loutoushe.com/page/"
self.BASE_DIR = "C:/Users/Administrator/Desktop/Pic/"
# 构造url
def beauty_girl_Spider(self):
for page in range(self.beginPage,self.endPage+1):
pageUrl=self.url+str(page)
self.load_page(pageUrl)
# 爬取页面文章链接
def load_page(self,pageUrl):
res = requests.get(pageUrl)
# 将获取到的str类型结果,转为Html类型,再通过xpath找出要的连接
html = etree.HTML(res.text)
links = html.xpath('//div[@class="post-inner"]/div/a/@href')
for i in links:
self.load_detial_page(i)
# 爬取帖子详情页,获得图片的链接
def load_detial_page(self,detail_pageUrl):
detail = requests.get(detail_pageUrl)
detail_html = etree.HTML(detail.text)
title = detail_html.xpath("//title")[0].text
pictures = detail_html.xpath('//div[@class="swiper-slide"]/img/@data-src')
#创建图片集的名字创建相应的目录
dirctory = self.BASE_DIR + title
os.mkdir(dirctory)
#遍历图片链接,下载图片
num=len(pictures)
for i in range(num):
print(f"正在下载{title},第{i+1}张.....")
self.load_picture(dirctory, pictures[i])
# 通过图片所在链接,爬取图片并保存图片到本地:
def load_picture(self,dictory, pic_link):
pic_name = pic_link.split('/')[-1]
path = f"{dictory}/{pic_name}" # 保存地址
pic = requests.get(pic_link)
file = open(path, "wb")
file.write(pic.content) # 下载图片
if __name__ == '__main__':
spider=Spider(5,6) #实例化图片爬虫对象,爬第5到第6页
spider.beauty_girl_Spider()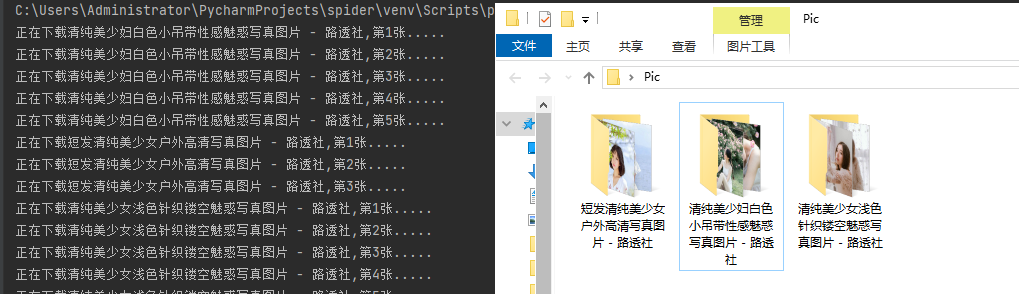
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END